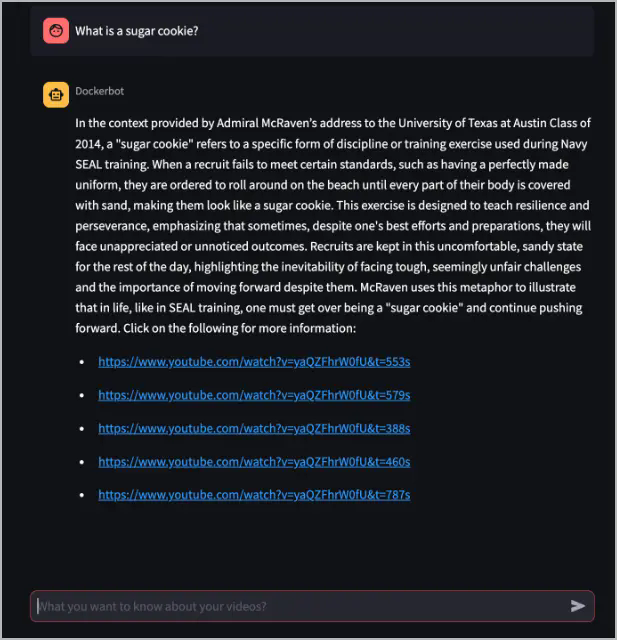
In this example, the Dockerbot answers the question and
provides links to the video with timestamps, which may contain more
information about the answer.
The dockerbot service takes the question, turns it into an embedding using
the text-embedding-3-small model, queries the Pinecone database to find
similar embeddings, and then passes that context into the gpt-4-turbo-preview
to generate an answer.
3. Select the first link to see what information it provides. Based on the
previous example, select
[https://www.youtube.com/watch?v=yaQZFhrW0fU&t=553s](https://www.youtube.com/watch?v=yaQZFhrW0fU&t=553s).
In the example link, you can see that the section of video perfectly answers
the question, "What is a sugar cookie?".
## Explore the application architecture
The following image shows the application's high-level service architecture, which includes:
- yt-whisper: A local service, ran by Docker Compose, that interacts with the
remote OpenAI and Pinecone services.
- dockerbot: A local service, ran by Docker Compose, that interacts with the
remote OpenAI and Pinecone services.
- OpenAI: A remote third-party service.
- Pinecone: A remote third-party service.
